TL;DR: We propose SMolInstruct, an instruction dataset for chemistry that focuses on small molecules; and LlaSMol, a series of large language models that substantially outperform existing LLMs on chemistry tasks. LLMs.
Chemistry plays a crucial role in many domains, such as drug discovery and material science. While large language models (LLMs) such as GPT-4 exhibit remarkable capabilities on natural language processing tasks, existing research indicates that their performance on chemistry tasks is discouragingly low. In this paper, however, we demonstrate that our developed LLMs can achieve very strong results on a comprehensive set of chemistry tasks, outperforming the most advanced GPT-4 and Claude 3 Opus by a substantial margin (e.g., 93.2% EM for converting SMILES to Formula vs. GPT-4's 4.8% and Claude 3 Opus's 9.2%; 32.9% EM for Retrosynthesis vs. GPT-4's ~0.0% and Claude 3 Opus's 1.1%). To accomplish this, we propose SMolInstruct, a large-scale, comprehensive, and high-quality dataset for instruction tuning. It contains 14 selected chemistry tasks and over three million samples, laying a solid foundation for training and evaluating LLMs for chemistry. Using SMolInstruct, we fine-tune a set of open-source LLMs, among which, we find that Mistral serves as the best base model for chemistry tasks. Our analysis further demonstrates the critical role of the proposed dataset in driving the performance improvements.
We propose SMolInstruct, an instruction dataset for chemistry that focuses on small molecules. It contains 14 meticulously selected tasks and over 3M carefully curated samples. The tasks are illustrated in the following figure.

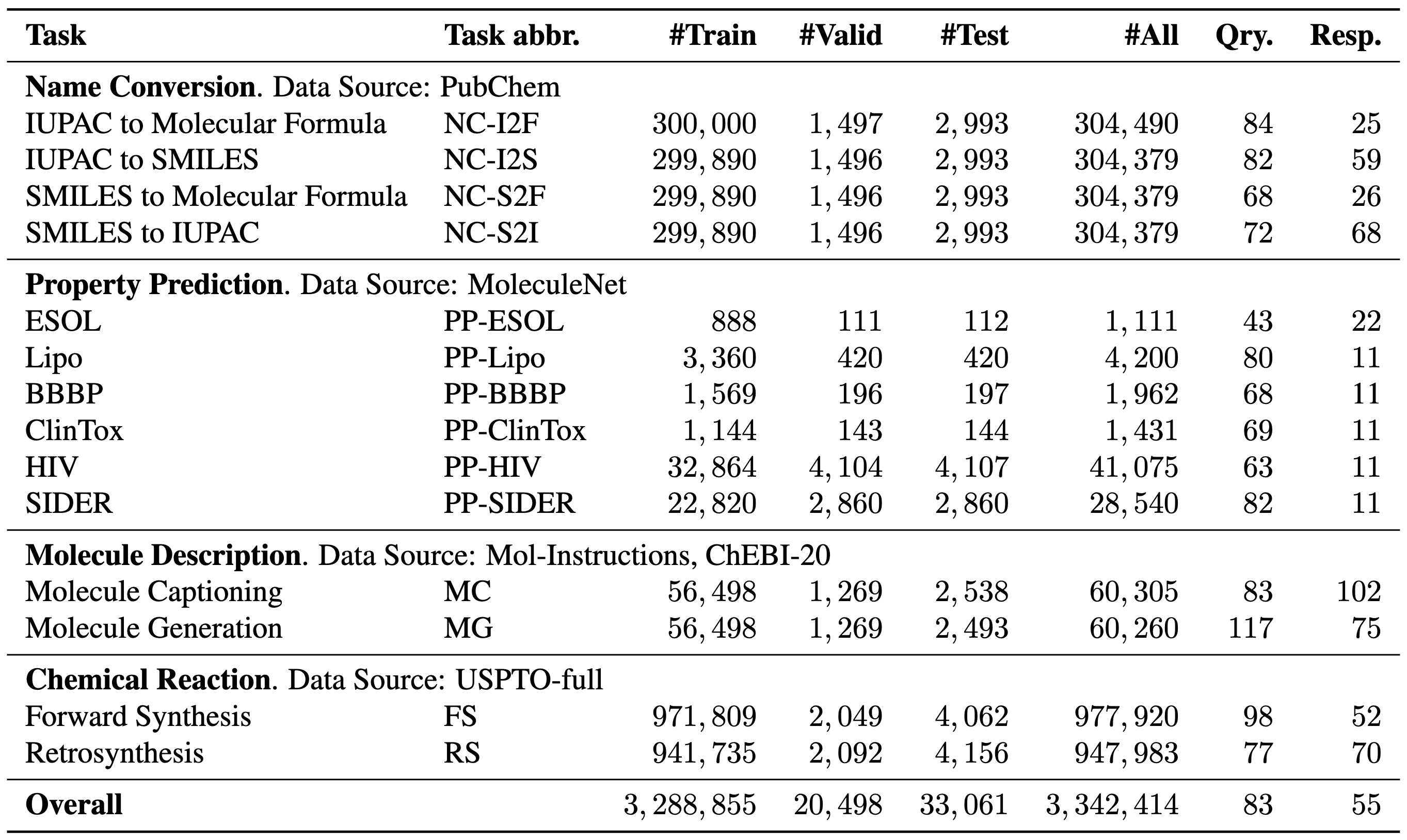
The following figure shows the statistics of SMolInstruct.
The merits of SMolInstruct:
Large-Scale. SMolInstruct consists of 3.3M samples and 1.6M distinct molecules, with a diverse range of sizes, structures, and properties, showcasing an extensive coverage of diverse chemical knowledge.
Comprehensive. SMolInstruct contains 4 types of chemical tasks (14 tasks in total), emerging as the most comprehensive instruction tuning dataset for small molecules. Notably, the tasks are meticulously selected to build a strong chemistry foundation model and to adapt to real-world applications.
High-Quality. Rigorous processing steps have been implemented to exclude problematic and low-quality samples. Along with careful data splitting and canonicalization of SMILES representations, SMolInstruct stands as a high-quality resource valuable for future research.
LlaSMol (large language models for small molecules) is a series of LLMs built for conducting various chemistry tasks. Specifically, we use Galactica, Llama 2, Code Llama, and Mistral as the base models, and conduct instruction tuning with LoRA on our SMolInstruct dataset. The resulting models are named as LlaSMolGalactica, LlaSMolLlama 2, LlaSMolCode Llama, LlaSMolMistral, respectively.




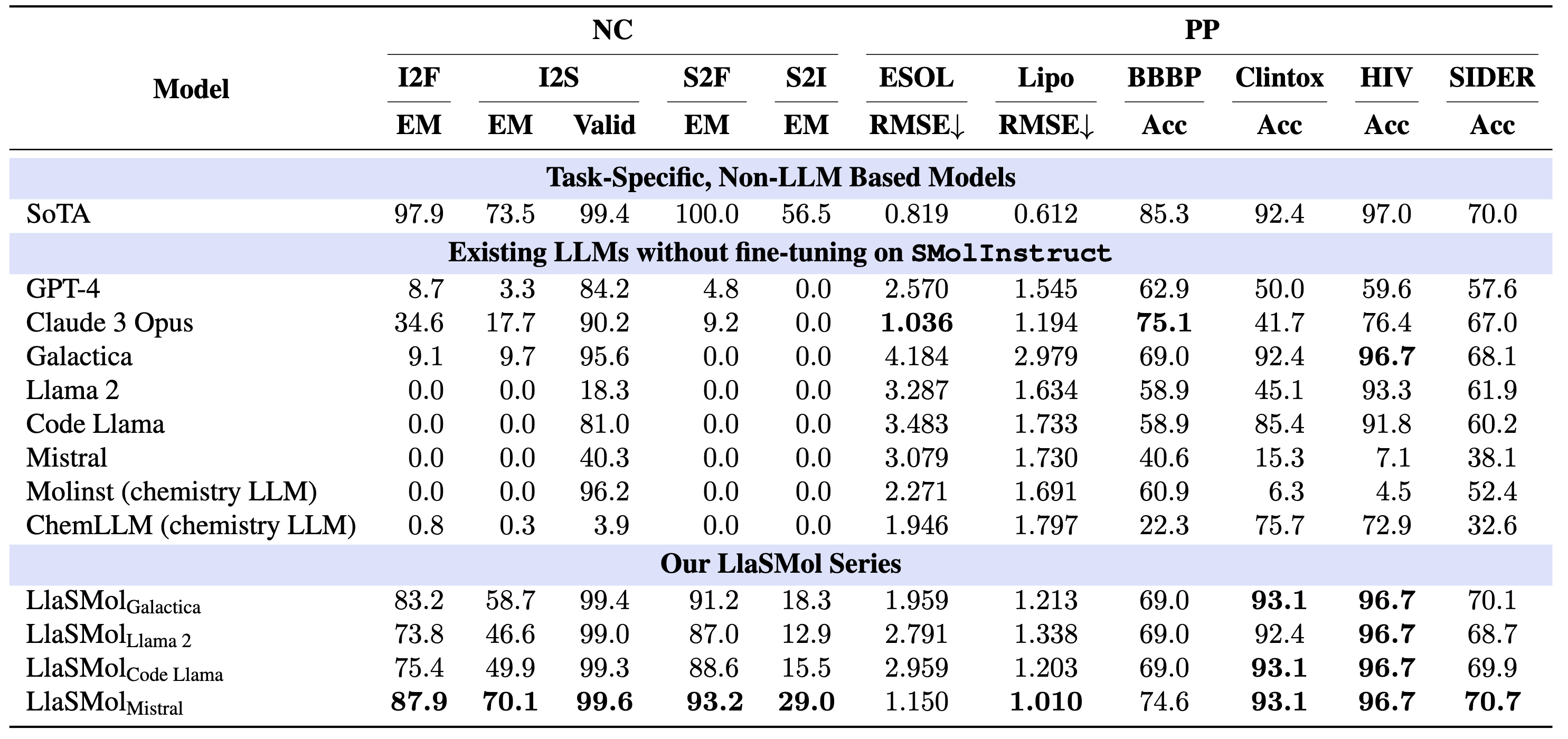
We comprehensively compare our LlasMol models with existing LLMs as well as the task-specific, non-LLM based SoTA models. The main results are shown in the following tables.
The following table shows the results for name conversion (NC) and property prediction (PP) tasks. The metrics include exact match (EM), validity (Valid), root mean square error (RMSE), and accuracy (Acc), where EM, Valid, and Acc are in percentage.
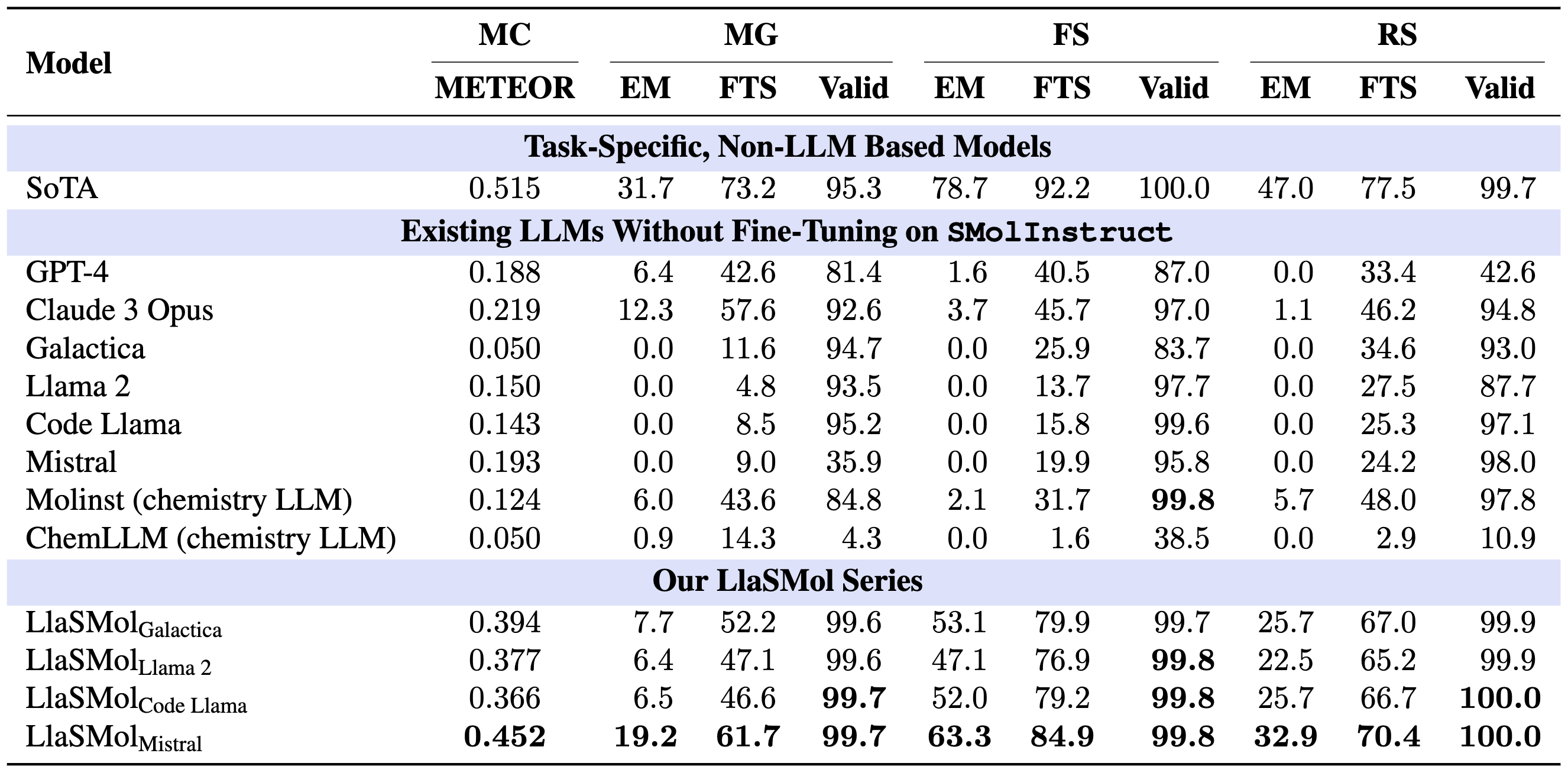
The following table shows results for molecule captioning (MC), molecule generation (MG), forward synthesis (FS), and retrosynthesis (RS). The metrics include METEOR score (METEOR), exact match (EM), Morgan fingerprint-based tanimoto similarity (FTS), and validity (Valid), where EM, FTS, and Valid are in percentage.
Main takeaways:
(1) LlaSMol models significantly outperform the existing LLMs on all the tasks, underscoring the effectiveness of the proposed SMolInstruct dataset and the benefits of fine-tuning.
(2) Our four LlaSMol models show substantial differences in their performance, and LlasMolMistral achieves the best, emphasizing the significant impact of base models on downstream tasks
(3) Although LlaSMol models do not outperform SoTA models on all the tasks, they demonstrate considerable potential for further improvements. Compared to previous efforts, they greatly narrowed the gap between LLMs and SoTA task-specific models. Remarkably, LlaSMolMistral attains such performance with only a small proportion of its parameters fine-tuned (41.9M, 0.58\%). Our further experiments suggest its immense potential to surpass task-specific models through more extensive fine-tuning and serve as a strong foundation model for chemistry applications.
Please check out our paper for findings regarding SMILES vs. SELFIES, the benefits of SMILES canonicalization, multi-task synergies, and more.
If our paper or related resources are valuable to your research/applications, we kindly ask for citation. Please feel free to contact us with any inquiries.
@article{yu2024llasmol,
title={LlaSMol: Advancing Large Language Models for Chemistry with a Large-Scale, Comprehensive, High-Quality Instruction Tuning Dataset},
author={Botao Yu and Frazier N. Baker and Ziqi Chen and Xia Ning and Huan Sun},
journal={arXiv preprint arXiv:2402.09391},
year={2024}
}
