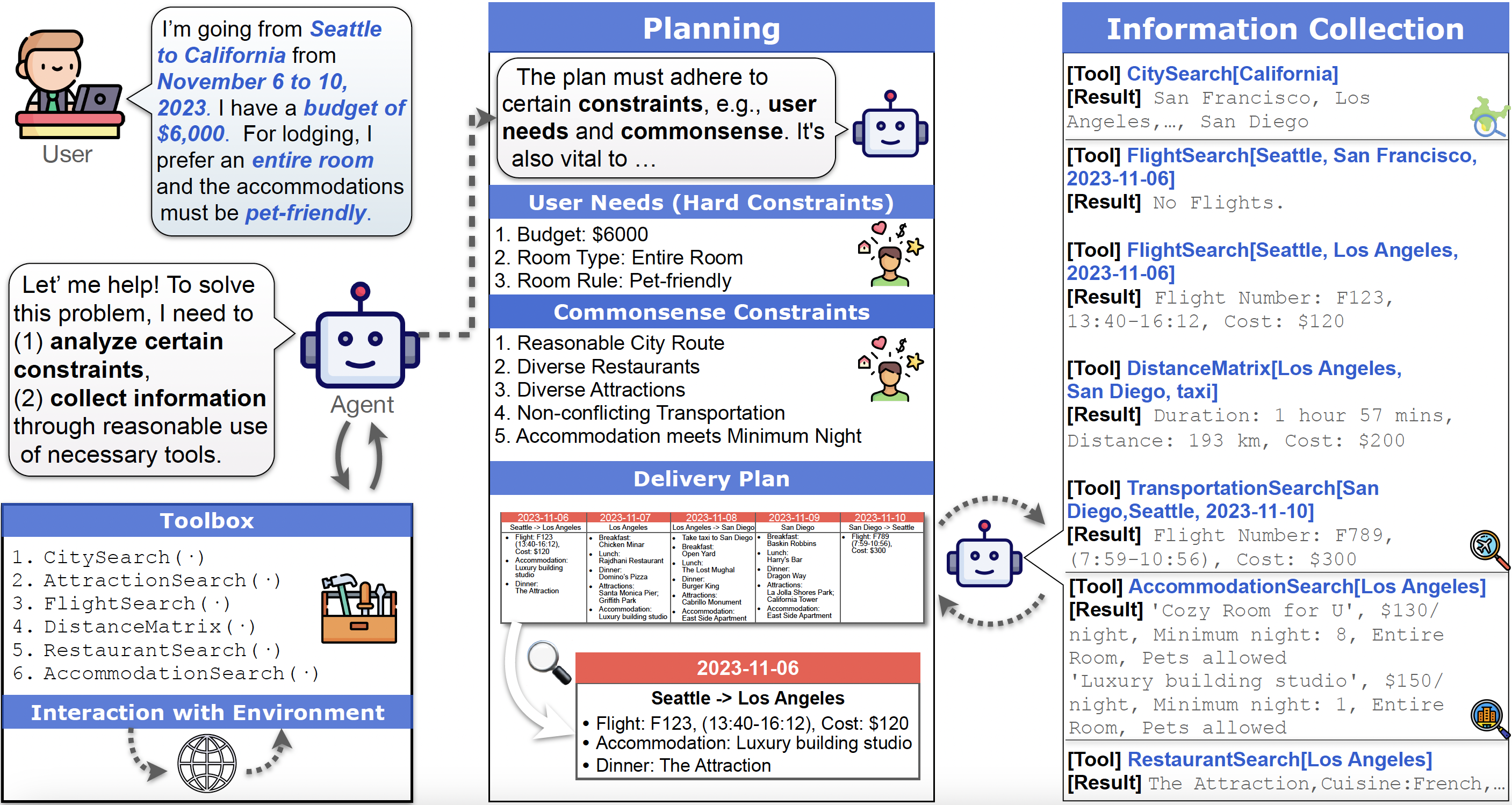
We introduce TravelPlanner: a comprehensive benchmark designed to evaluate the planning abilities of language agents in real-world scenarios across multiple dimensions. Without losing generality, TravelPlanner casts travel planning as its test environment, with all relevant information meticulously crafted to minimize data contamination. TravelPlanner does not have a singular ground truth for each query. Instead, the benchmark employs several pre-defined evaluation scripts to assess each tested plan, determining whether the language agent can effectively use tools to create a plan that aligns with both the implicit commonsense and explicit user needs outlined in the query (i.e., commonsense constraint and hard constraint). Every query in TravelPlanner has undergone thorough human verification to guarantee that feasible solutions exist. Additionally, TravelPlanner evaluates the language agent's capability by varying the breadth and depth of planning, controlled through the number of travel days and the quantity of hard constraints.
We introduce ![]() TravelPlanner, a benchmark crafted for evaluating language agents in tool-use and complex
planning within multiple constraints.
Grounded in travel planning, a real world use-case that naturally includes diverse constraints such as
user needs and commonsense constraints in the environment, TravelPlanner evaluates whether language agents
can develop reasonable travel plans by collecting information via diverse tools and making decisions,
while satisfying the constraints.
For a given query, language agents are expected to formulate a comprehensive plan that includes
transportation, daily meals, attractions, and accommodation for each day.
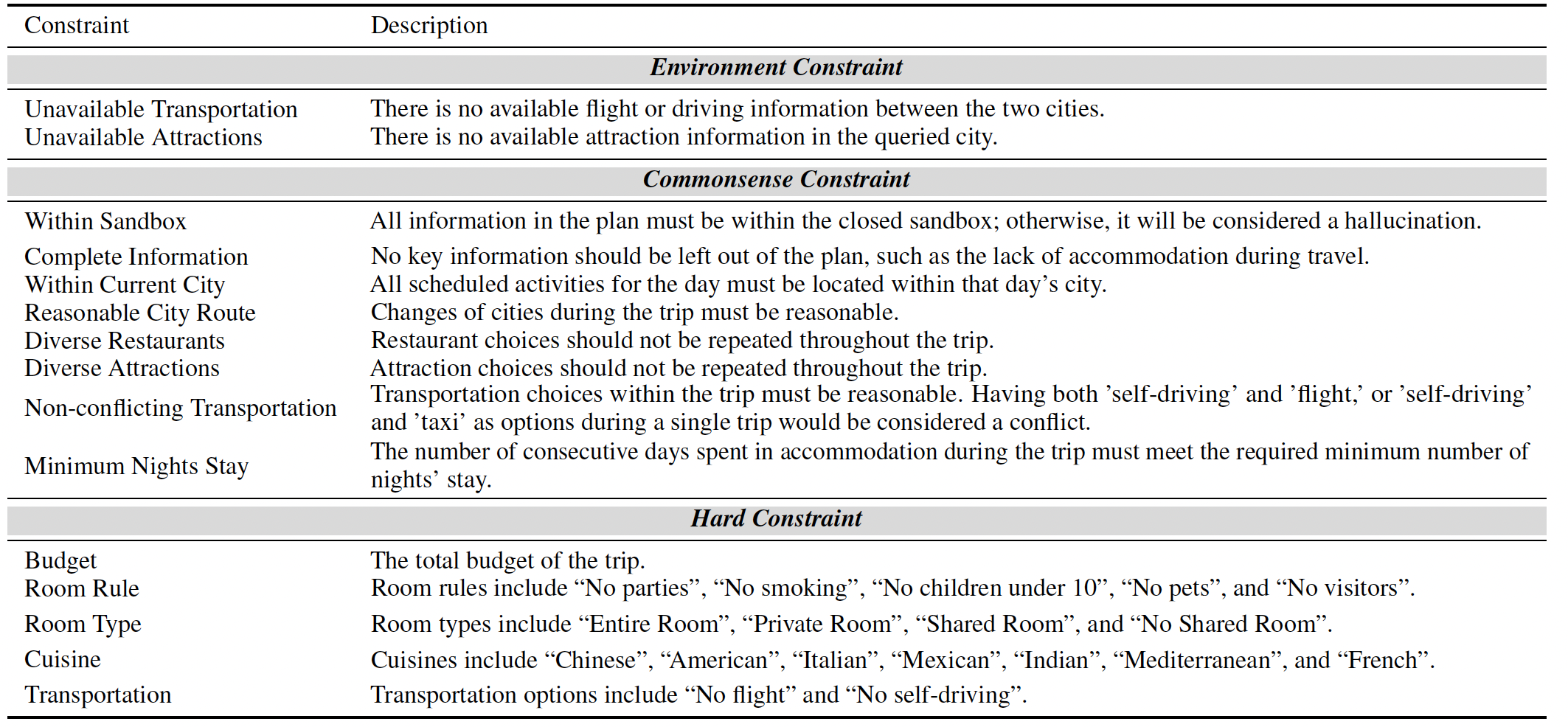
For constraints, from the perspective of real world applications, we design three types of them:
Environment Constraint, Commonsense Constraint, and Hard Constraint.
TravelPlanner comprises 1,225 queries in total. The number of days and hard constraints are designed to test
agents' abilities across both the breadth and depth of complex planning.
TravelPlanner, a benchmark crafted for evaluating language agents in tool-use and complex
planning within multiple constraints.
Grounded in travel planning, a real world use-case that naturally includes diverse constraints such as
user needs and commonsense constraints in the environment, TravelPlanner evaluates whether language agents
can develop reasonable travel plans by collecting information via diverse tools and making decisions,
while satisfying the constraints.
For a given query, language agents are expected to formulate a comprehensive plan that includes
transportation, daily meals, attractions, and accommodation for each day.
For constraints, from the perspective of real world applications, we design three types of them:
Environment Constraint, Commonsense Constraint, and Hard Constraint.
TravelPlanner comprises 1,225 queries in total. The number of days and hard constraints are designed to test
agents' abilities across both the breadth and depth of complex planning.
And the benchmark is divided into the training, validation, and test set.
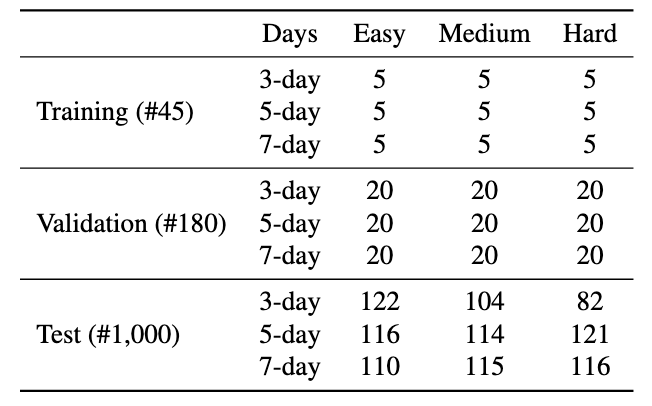
Dataset distribution of TravelPlanner.
Examples in train set:
Easy Level & 3-day
Easy Level & 5-day
Easy Level & 7-day
Medium Level & 3-day
Medium Level & 5-day
Medium Level & 7-day
Hard Level & 3-day
Hard Level & 5-day
Hard Level & 7-day
![]() TravelPlanner
constraint description. The environment constraint is manifested through the feedback received from the
environment, assessing whether the language agent can adjust its plan appropriately. The commonsense
constraint and hard constraint are evaluated based on how well the language agent's plan aligns with
these specific criteria.
TravelPlanner
constraint description. The environment constraint is manifested through the feedback received from the
environment, assessing whether the language agent can adjust its plan appropriately. The commonsense
constraint and hard constraint are evaluated based on how well the language agent's plan aligns with
these specific criteria.

![]() Tool description and the number of items in the database. The original data for each tool is sourced from publicly available internet data. We then modify this data, which includes adding, deleting, and altering certain keys and values to suit our requirements. In this way, we effectively avoid the problem of data contamination.
Tool description and the number of items in the database. The original data for each tool is sourced from publicly available internet data. We then modify this data, which includes adding, deleting, and altering certain keys and values to suit our requirements. In this way, we effectively avoid the problem of data contamination.
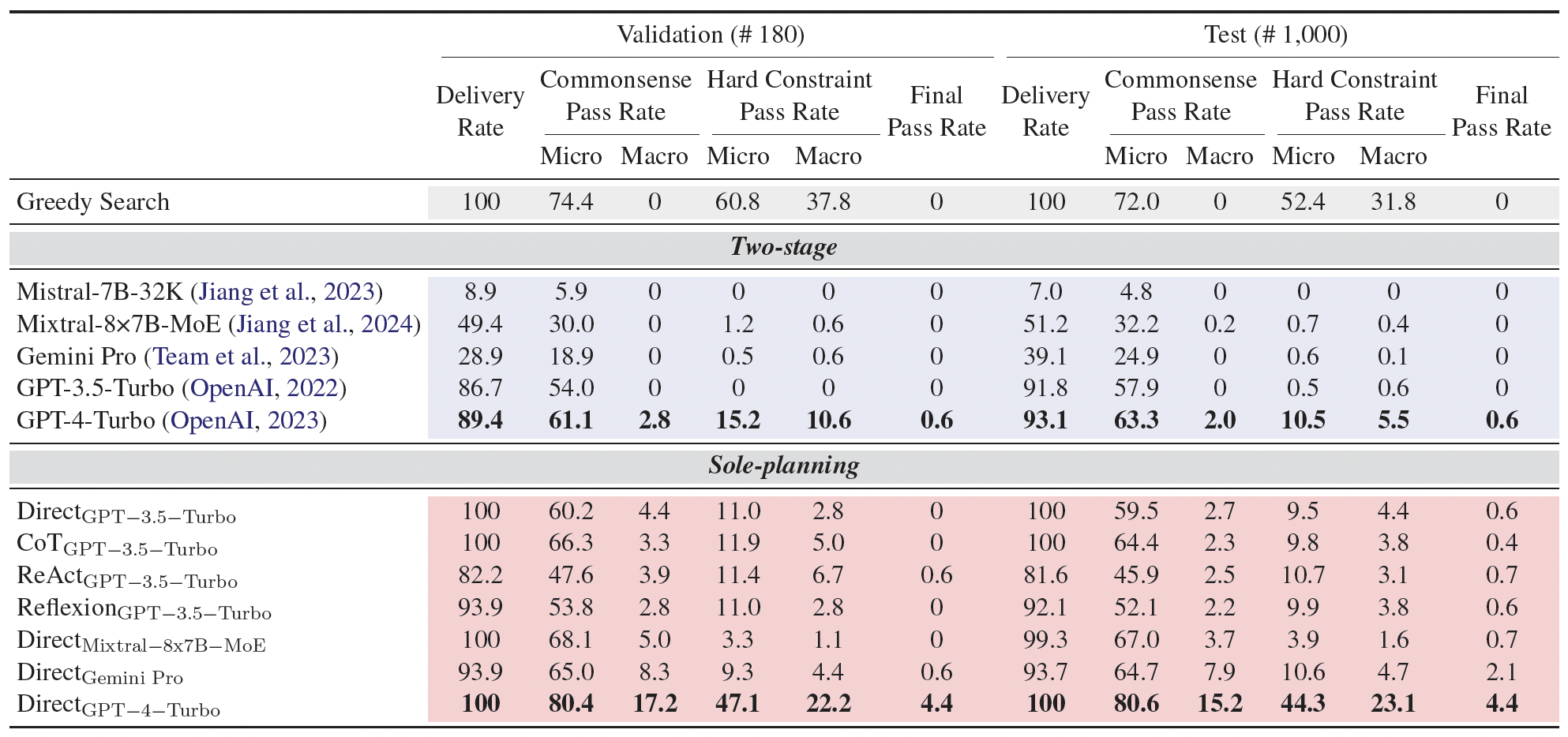
Main results of different LLMs and planning strategies on the TravelPlanner validation and test set. The best results are marked in bold.
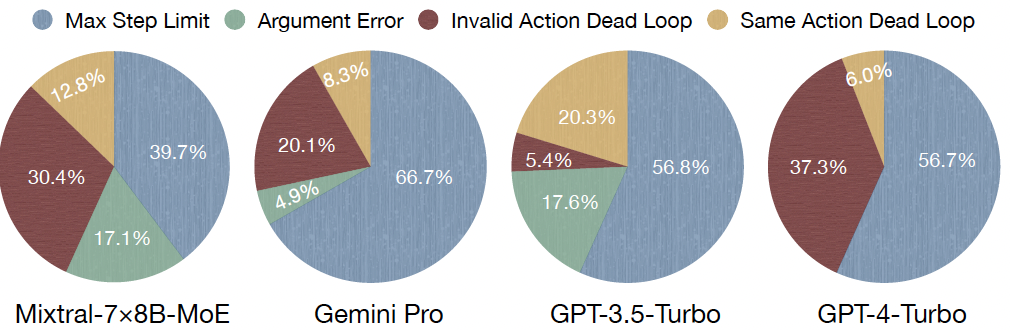
Tool-use error distribution on test set. We set the maximum tool-use process step as 30. An agent will trigger an early stop if it either makes three consecutive failed attempts or repeats an action thrice consecutively, indicating a dead loop.
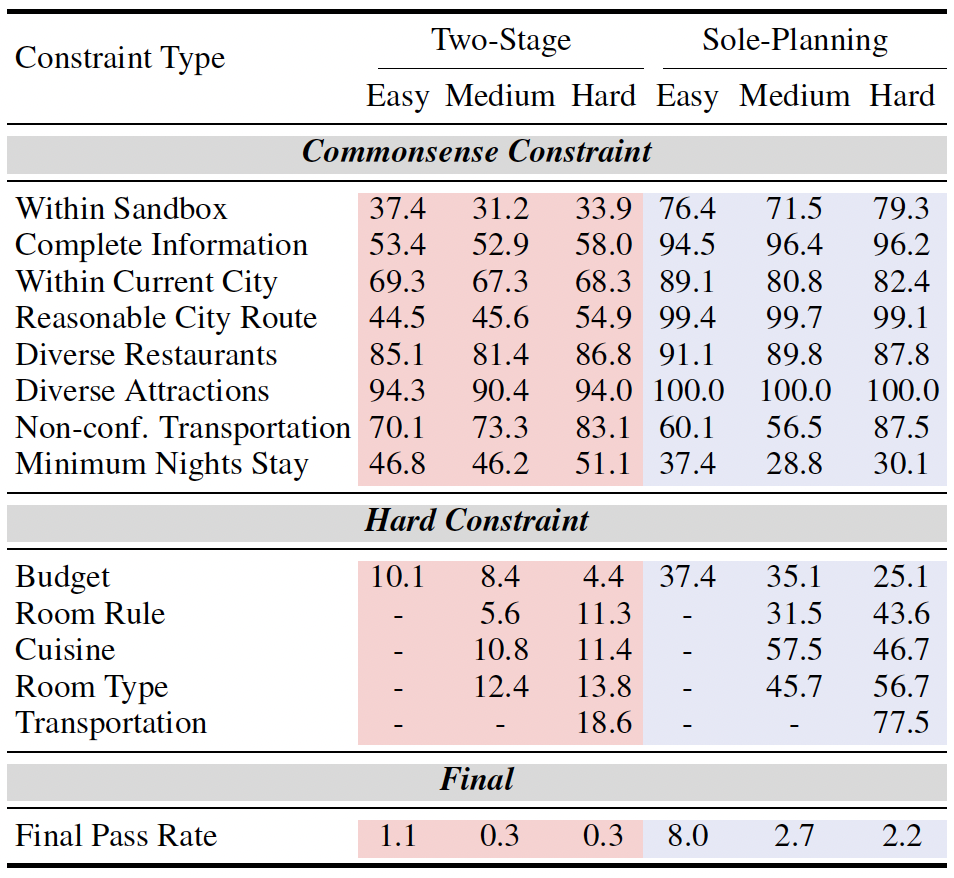
Constraint pass rate of GPT-4-Turbo on test set. The results of sole-planning mode are based on Direct strategy. Note that plans failing to meet the "Within Sandbox" or "No Missed Key Information" criteria are excluded from the hard constraint pass rate calculation. This exclusion is due to the fact that information beyond the sandbox's scope or key details that are missed cannot be effectively searched or evaluated.
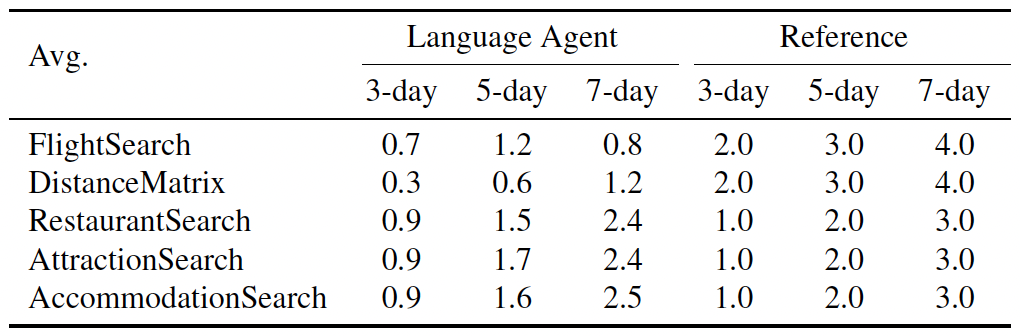
Comparison of the numbers of different tool uses between agent (GPT-4-Turbo) and reference. The results of agent are based on the number of entries written into the "Notebook".

GPT-4-Turbo + ReAct in tool-use scenario.

GPT-4-Turbo + ReAct in tool-use scenario.

GPT-4-Turbo + ReAct in tool-use scenario.

GPT-4-Turbo + ReAct in tool-use scenario.

GPT-4-Turbo + Direct Planning in sole-planning scenario.
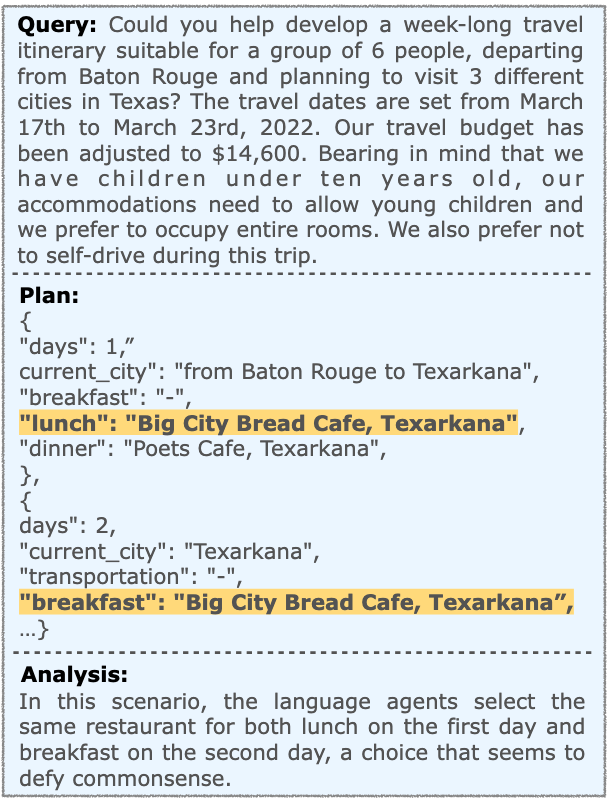
GPT-4-Turbo + Direct Planning in sole-planning scenario.
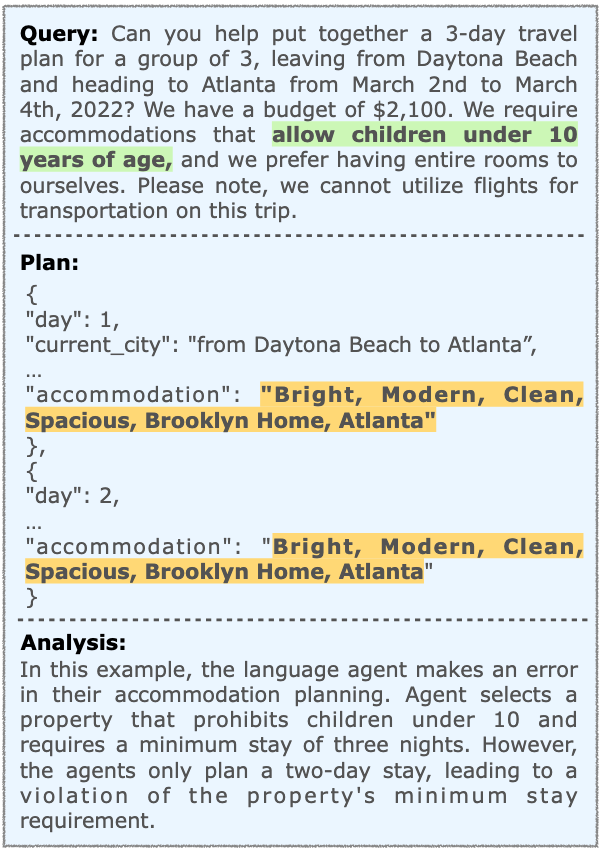
GPT-4-Turbo + Direct Planning in sole-planning scenario.

GPT-4-Turbo + Direct Planning in sole-planning scenario.
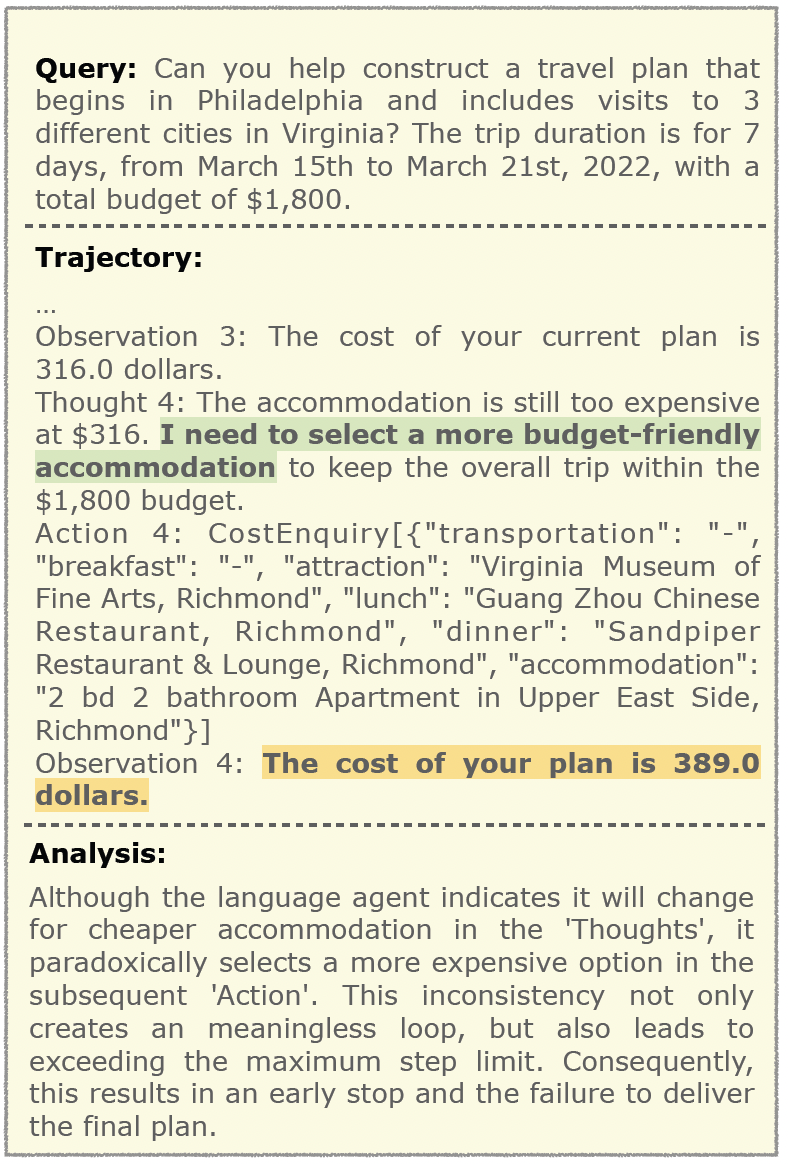
GPT-4-Turbo + Reflexion Planning in sole-planning scenario.

GPT-4-Turbo + Reflexion Planning in sole-planning scenario.
@inproceedings{xie2024travelplanner,
title={TravelPlanner: A Benchmark for Real-World Planning with Language Agents},
author={Xie, Jian and Zhang, Kai and Chen, Jiangjie and Zhu, Tinghui and Lou, Renze and Tian, Yuandong and Xiao, Yanghua and Su, Yu},
booktitle={Forty-first International Conference on Machine Learning},
year={2024}
}