SeeAct first performs Action Generation by leveraging an LMM, like GPT-4V, to visually perceive websites and generate plans in textual forms. We explicitly instruct GPT-4V to imitate humans browsing a webpage and analyze the task, webpage, and previous actions. It is asked to generate an action description based on its analysis and reasoning. Action Grounding is the next step to ground textual plans to the HTML elements and operations to act on the website.
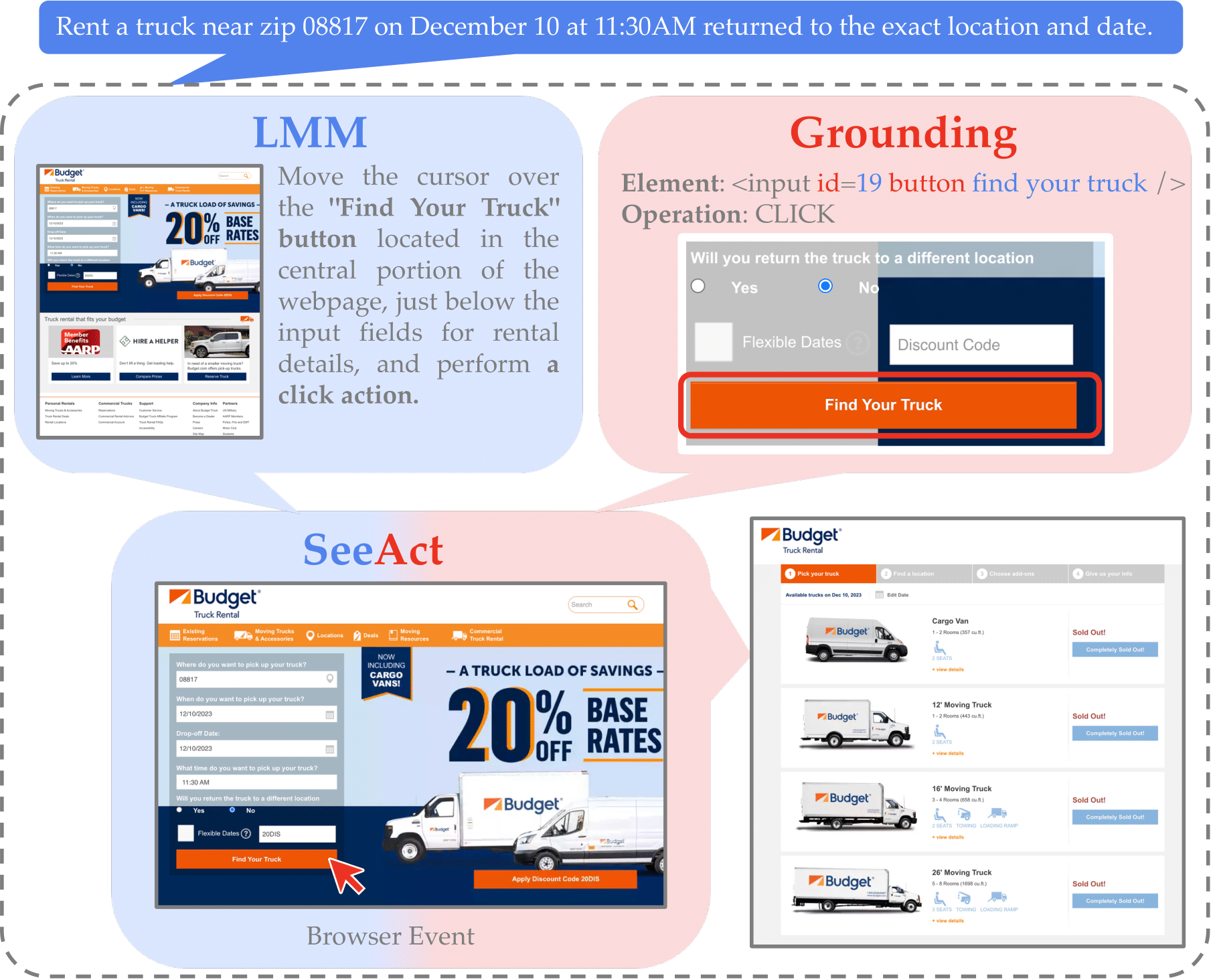
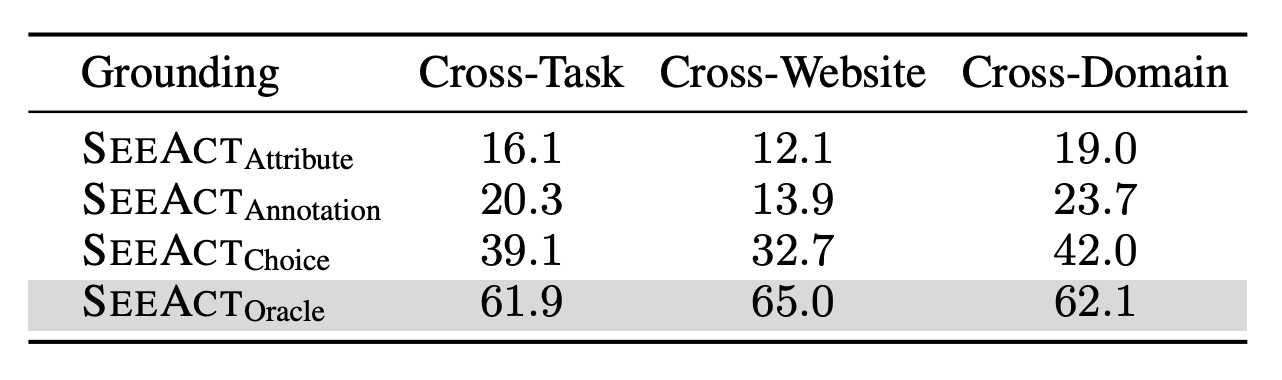
Despite the capability of LMMs in identifying and describing the next action to complete the given task in natural language, it is still challenging to convert the action description into an executable action within the environment. To address the challenge of action grounding, we explore three approaches using different types of information: Grounding via Element Attributes, Grounding via Textual Choices, and Grounding via Image Annotation.


An example of action generation in grounding via textual choices.

An example of grounding via textual choices after action generation.

An example of action generation in grounding via image annotation.

An example of grounding via image annotation after action generation.

An example of action generation in grounding via element attributes.

An example of grounding via element attributes after action generation.
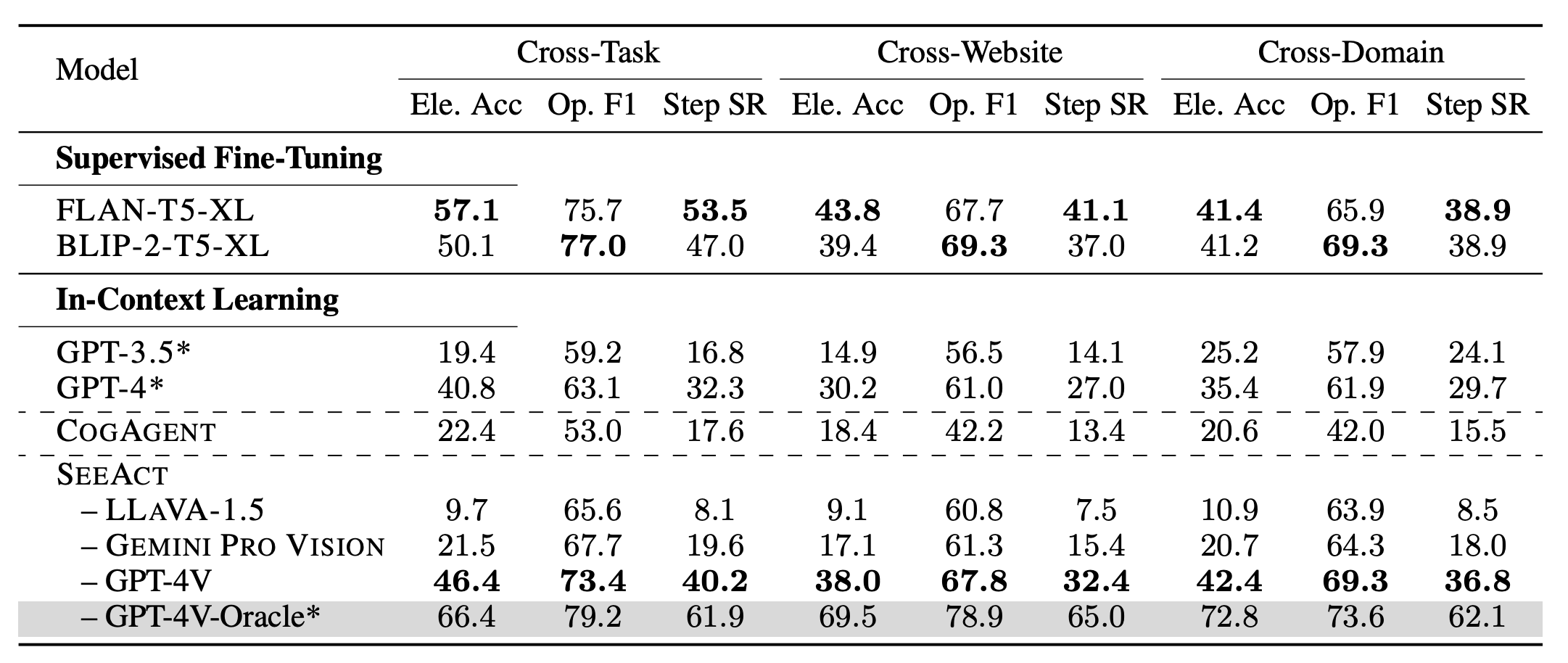
We compare SeeAct with other models following MindAct's two-stage strategy. We evaluate supervised fine-tuning (SFT) methods using FLAN-T5 and BLIP-2-T5 and in-context learning (ICL) methods using GPT-3.5, GPT-4.
We develop a new online evaluation tool using Playwright to evaluate web agents on live websites. Our tool can convert the predicted action into a browser event and execute it on the website. To adhere to ethical standards, our experiments are restricted to non-login tasks in compliance with user agreements, and we closely monitor agent activities during online evaluation to prevent any actions that have potentially harmful impacts.
.
SeeAct can successfully complete 50% of tasks on different websites if provided an oracle grounding method. We further investigate the performance of web agents on tasks across different difficulty levels. We estimate the task difficulty based on the number of actions taken by annotators during action trace annotation.
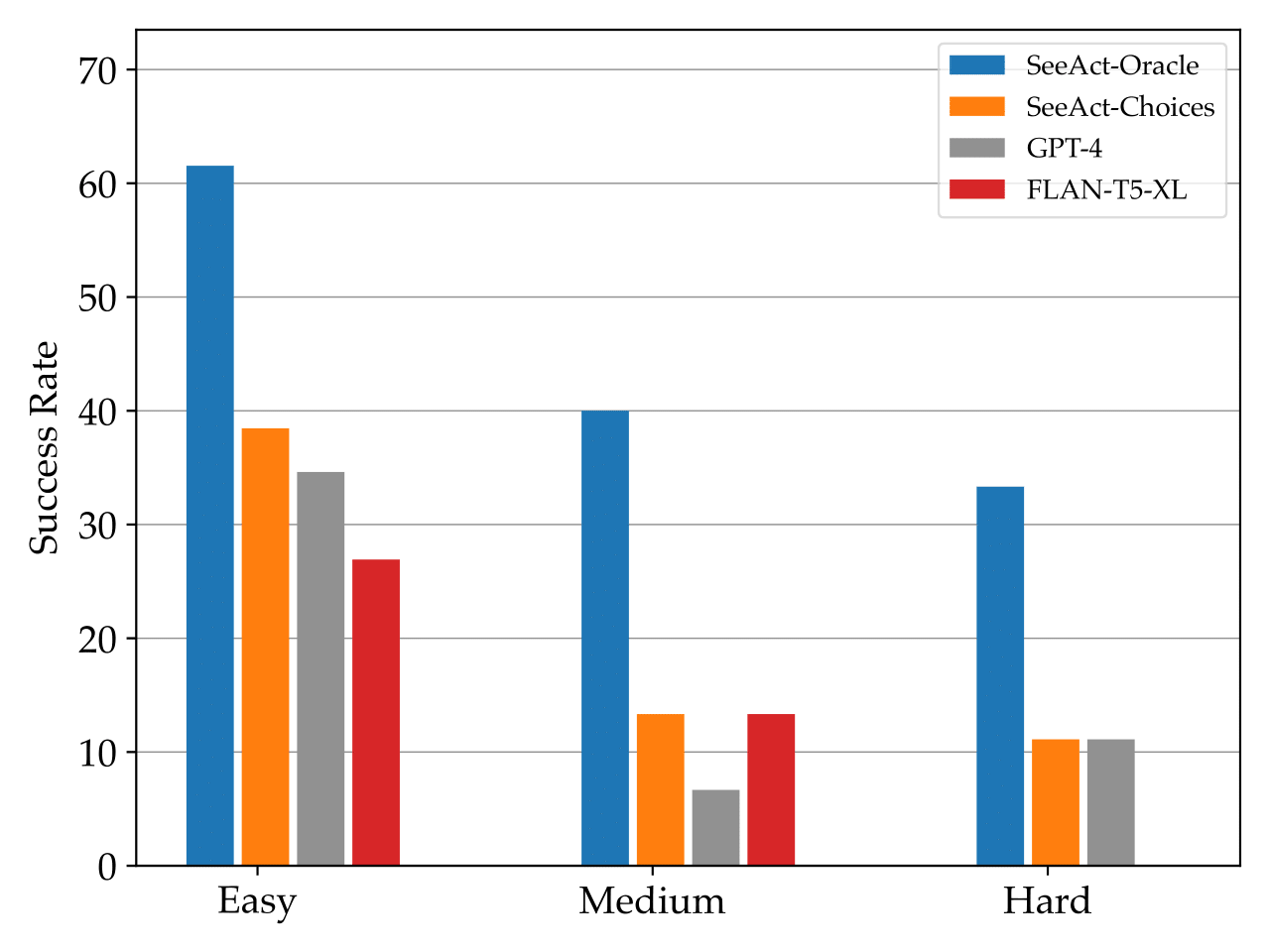
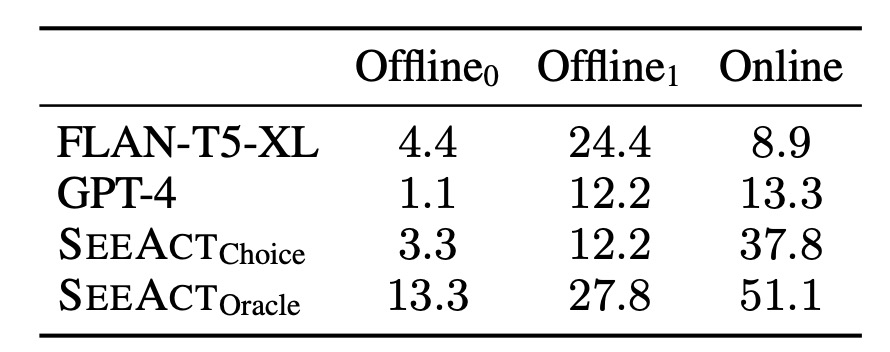
GPT-4V exhibits promising capabilities, ranging from speculative planning, webpage content reasoning, and error correction to surpassing the limitations of superficial textual similarity matching inherent in fine-tuned, text-only models.

In this example, the model generates a comprehensive plan for the task, including subsequent actions on the following pages that are not currently visible.

In this case, the textual history does not adequately capture two critical pieces of information. Firstly, the website automatically sets the drop-off date to the same day. Secondly, the ’No’ button was selected (However, it was missed in previous actions due to the button’s lack of text). Nevertheless, the model discerns these details through a meticulous screenshot analysis, enabling it to make the correct decision for the next step.

In this example, the task requires knowledge of the IATA code for Los Cabos International Airport. GPT-4V accurately provides the correct code.

In this example, the webpage displays an error message indicating an invalid phone number, a consequence of prior actions. The model identifies this error and prioritizes its immediate rectification, foregoing the subsequent planned steps.

In this example, the model describes a correct element in action generation. However, the identified element is absent from the set of candidate elements. Despite this, the model erroneously assigns it the index number "12".

In this example, the model predicts the appropriate element. Nevertheless, the identified element is not present in the provided image options. Despite this, the model erroneously assigns it with the label ’5’ nearby.

In this case, while the model predicts the appropriate element, it incorrectly associates the element with the nearby label '10' instead of the correct label '11'.

In this case, while the model predicts the appropriate element, it incorrectly associates the element with the nearby label '7' instead of the correct label '6'.
@article{zheng2023seeact,
title={GPT-4V(ision) is a Generalist Web Agent, if Grounded},
author={Boyuan Zheng and Boyu Gou and Jihyung Kil and Huan Sun and Yu Su},
journal={arXiv preprint arXiv:2401.01614},
year={2024},
}
@inproceedings{deng2023mindweb,
title={Mind2Web: Towards a Generalist Agent for the Web},
author={Xiang Deng and Yu Gu and Boyuan Zheng and Shijie Chen and Samuel Stevens and Boshi Wang and Huan Sun and Yu Su},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=kiYqbO3wqw}
}