In this work, we introduce TableLlama and TableInstruct, the first large open-source generalist model and instruction tuning dataset for tables. Everything is open-source right now!
TableInstruct is a large-scale instruction tuning dataset with diverse, realistic tasks based on real-world tables. TableInstruct boasts a collection of 14 datasets of 11 tasks in total, which is curated from 1.24M tables containing 2.6M instances:
TableLlama is a large generalist model for tables based on Llama 2 (7B) and LongLoRA, which can:
8k);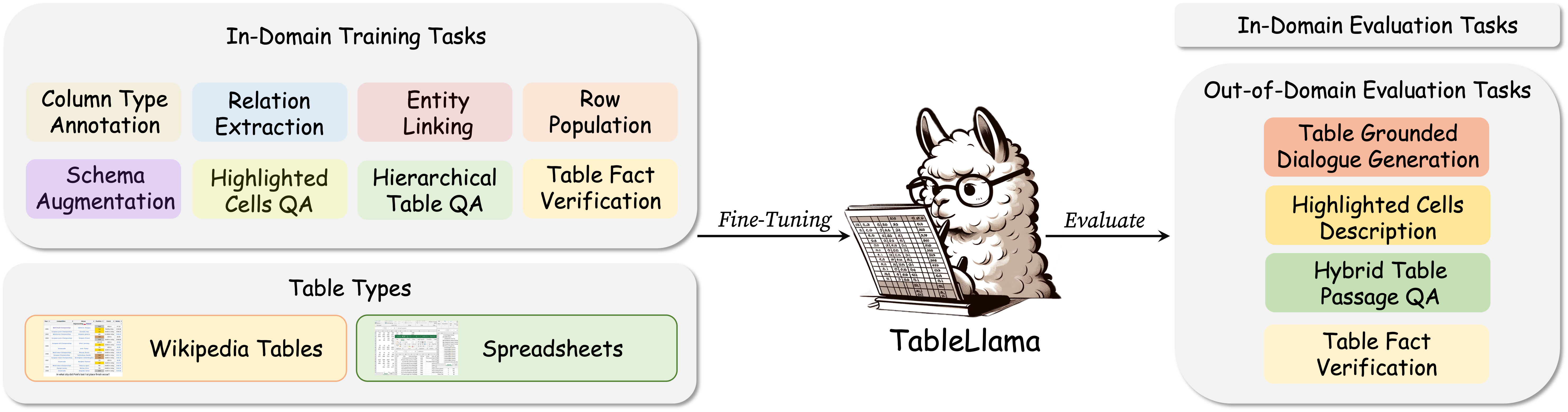
Figure 1: An overview of TableInstruct and TableLlama. TableInstruct includes a wide variety of realistic tables and tasks with instructions. We make the first step towards developing open-source generalist models for tables with TableInstruct and TableLlama.
Semi-structured tables are ubiquitous. There has been a variety of tasks that aim to automatically interpret, augment, and query tables. Current methods often require pretraining on tables or special model architecture design, are restricted to specific table types, or have simplifying assumptions about tables and tasks. This paper makes the first step towards developing open-source large language models (LLMs) as generalists for a diversity of table-based tasks. Towards that end, we construct TableInstruct, a new dataset with a variety of realistic tables and tasks, for instruction tuning and evaluating LLMs. We further develop the first open-source generalist model for tables, TableLlama, by fine-tuning Llama 2 (7B) with LongLoRA to address the long context challenge. We experiment under both in-domain setting and out-of-domain setting. On 7 out of 8 in-domain tasks, TableLlama achieves comparable or better performance than the SOTA for each task, despite the latter often has task-specific design. On 6 out-of-domain datasets, it achieves 5-44 absolute point gains compared with the base model, showing that training on TableInstruct enhances the model’s generalizability. We open-source our dataset and trained model to boost future work on developing open generalist models for tables.
Updates
Note:
We construct TableInstruct, a comprehensive table-based instruction tuning dataset that covers a variety of real-world tables and realistic tasks. We include 14 datasets of 11 tasks in total, with both in-domain and out-of-domain evaluation settings. Some examples can be found in the figure below:

Figure 2: Illustration of three exemplary tasks: (a) Column type annotation. This task is to annotate the selected column with the correct semantic types. (b) Row population. This task is to populate rows given table metadata and partial row entities. (c) Hierarchical table QA. For subfigures (a) and (b), we mark candidates with red color in the "task instruction" part. The candidate set size can be hundreds to thousands in TableInstruct.
TableInstruct includes various kinds of table tasks to comprehensively represent different table-related applications in real-world scenarios. These tasks belong to several categories: table interpretation, table augmentation, question answering, fact verification, dialogue generation, and data-to-text. The table below shows the statistics of TableInstruct:
@misc{zhang2023tablellama,
title={TableLlama: Towards Open Large Generalist Models for Tables},
author={Tianshu Zhang and Xiang Yue and Yifei Li and Huan Sun},
year={2023},
eprint={2311.09206},
archivePrefix={arXiv},
primaryClass={cs.CL}
}